
124
عدد المشاهدات

تاريخ آخر تحديث

من أكبر أخطاء مالكي مواقع الويب الجدد عدم النظر في ملف robots.txt الخاص بهم. فما هو على أي حال ، ولماذا مهم جدا؟ لدينا إجاباتك.
إذا كنت تمتلك موقعًا إلكترونيًا وتهتم بصحة تحسين محركات البحث لموقعك ، فيجب أن تكون على دراية كبيرة بملف robots.txt على نطاقك. صدق أو لا تصدق ، فهناك عدد كبير ومقلق من الأشخاص الذين يطلقون نطاقًا بسرعة ، ويثبتون موقع WordPress سريعًا ، ولا يكلفون عناء فعل أي شيء مع ملف robots.txt الخاص بهم.
هذا أمر خطير. يمكن أن يؤدي ملف robots.txt الذي تمت تهيئته بشكل سيئ إلى تدمير صحة تحسين محركات البحث لموقعك ، وإتلاف أي فرص قد تكون لديك لزيادة حركة المرور.
ال ملف robots.txt تم تسمية الملف بشكل ملائم لأنه في الأساس ملف يسرد توجيهات لروبوتات الويب (مثل روبوتات محرك البحث) حول كيفية وما يمكنهم الزحف إليه على موقع الويب الخاص بك. لقد كان هذا معيار ويب متبوعًا بمواقع الويب منذ عام 1994 وجميع برامج زحف الويب الرئيسية تلتزم بالمعيار.
يتم تخزين الملف بتنسيق نصي (بملحق .txt) في المجلد الجذر لموقعك على الويب. في الواقع ، يمكنك عرض ملف robot.txt لأي موقع ويب فقط عن طريق كتابة النطاق متبوعًا بـ /robots.txt. إذا جربت ذلك باستخدام groovyPost ، فسترى مثالًا لملف robot.txt منظم جيدًا.
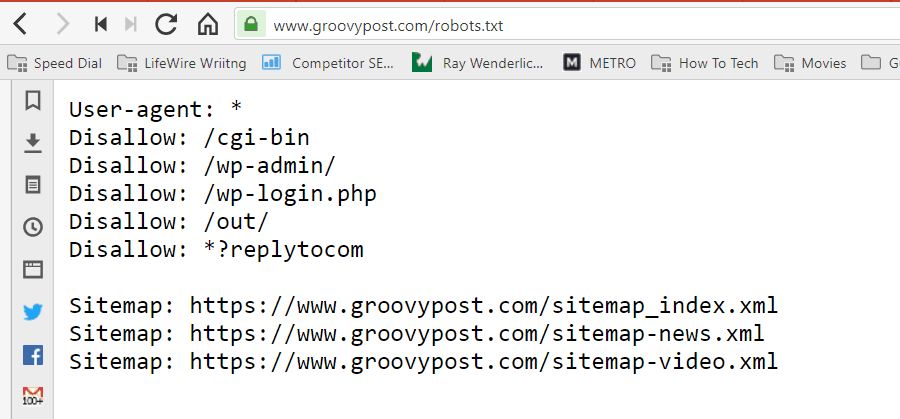
الملف بسيط ولكنه فعال. لا يميز ملف المثال هذا بين الروبوتات. يتم إصدار الأوامر لجميع الروبوتات باستخدام وكيل المستخدم: * التوجيه. وهذا يعني أن جميع الأوامر التي تتبعه تنطبق على جميع الروبوتات التي تزور الموقع للزحف إليه.
يمكنك أيضًا تحديد قواعد محددة لبرامج زحف الويب المحددة. على سبيل المثال ، قد تسمح لـ Googlebot (زاحف الويب من Google) بالزحف إلى جميع المقالات على موقعك ، ولكنك قد ترغب في ذلك منع زاحف الويب الروسي Yandex Bot من الزحف إلى مقالات على موقعك تحتوي على معلومات مهينة حول روسيا.
هناك المئات من برامج زحف الويب التي تجوب الإنترنت للحصول على معلومات حول مواقع الويب ، ولكن العشرة الأكثر شيوعًا التي يجب أن تقلق بشأنها مدرجة هنا.
إذا أخذنا المثال الوارد أعلاه ، إذا كنت تريد السماح لـ Googlebot بفهرسة كل شيء على موقعك ، ولكنك تريد ذلك منع Yandex من فهرسة محتوى مقال باللغة الروسية ، ستضيف الأسطر التالية إلى ملف robots.txt الخاص بك ملف.
وكيل المستخدم: googlebot
Disallow: Disallow: / wp-admin /
Disallow: /wp-login.php
وكيل المستخدم: yandexbot
Disallow: Disallow: / wp-admin /
Disallow: /wp-login.php
Disallow: / روسيا /
كما ترى ، فإن القسم الأول يمنع Google فقط من الزحف إلى صفحة تسجيل الدخول إلى WordPress والصفحات الإدارية. يحظر القسم الثاني Yandex من نفس الشيء ، ولكن أيضًا من المنطقة الكاملة لموقعك حيث قمت بنشر مقالات ذات محتوى مناهض لروسيا.
هذا مثال بسيط لكيفية استخدام عدم السماح الأمر للتحكم في برامج زحف الويب المحددة التي تزور موقعك على الويب.
إن Disallow ليس الأمر الوحيد الذي يمكنك الوصول إليه في ملف robots.txt. يمكنك أيضًا استخدام أي من الأوامر الأخرى التي ستوجه كيفية زحف الروبوت إلى موقعك.
ضع في اعتبارك أن الروبوتات سوف فقط استمع إلى الأوامر التي قدمتها عند تحديد اسم الروبوت.
من الأخطاء الشائعة التي يرتكبها الأشخاص عدم السماح بمناطق مثل / wp-admin / من جميع برامج الروبوت ، ولكن بعد ذلك حدد قسم googlebot وحظر مناطق أخرى فقط (مثل / about /).
نظرًا لأن برامج التتبع تتبع الأوامر التي تحددها فقط في قسمها ، فأنت بحاجة إلى إعادة تعيين جميع الأوامر الأخرى التي حددتها لجميع برامج التتبع (باستخدام * وكيل المستخدم).
ضع في اعتبارك أن ملف robots.txt يهدف إلى مساعدة برامج التتبع الشرعية (مثل روبوتات محرك البحث) في الزحف إلى موقعك بشكل أكثر فعالية.
هناك الكثير من برامج الزحف الشائنة التي تزحف إلى موقعك للقيام بأشياء مثل التخلص من عناوين البريد الإلكتروني أو سرقة المحتوى الخاص بك. إذا كنت ترغب في محاولة استخدام ملف robots.txt الخاص بك لمنع برامج الزحف هذه من الزحف إلى أي شيء على موقعك ، فلا تقلق. عادةً ما يتجاهل منشئو برامج الزحف هذه أي شيء تضعه في ملف robots.txt.
يعد جعل محرك بحث Google يقوم بالزحف على أكبر قدر ممكن من المحتوى على موقعك على الويب مصدر قلق رئيسي لمعظم مالكي مواقع الويب.
ومع ذلك ، تنفق Google فقط محدودة ميزانية الزحف و معدل الزحف على مواقع فردية. معدل الزحف هو عدد الطلبات التي يقدمها Googlebot لكل ثانية إلى موقعك أثناء حدث الزحف.
الأهم من ذلك هو ميزانية الزحف ، وهي عدد الطلبات الإجمالية التي سيقدمها Googlebot للزحف إلى موقعك في جلسة واحدة. تنفق Google ميزانيتها الخاصة بالزحف من خلال التركيز على مناطق شائعة جدًا أو تغيرت مؤخرًا في موقعك.
أنت لست أعمى على هذه المعلومات. إذا قمت بزيارة أدوات مشرفي المواقع من Google، يمكنك أن ترى كيف يتعامل الزاحف مع موقعك.
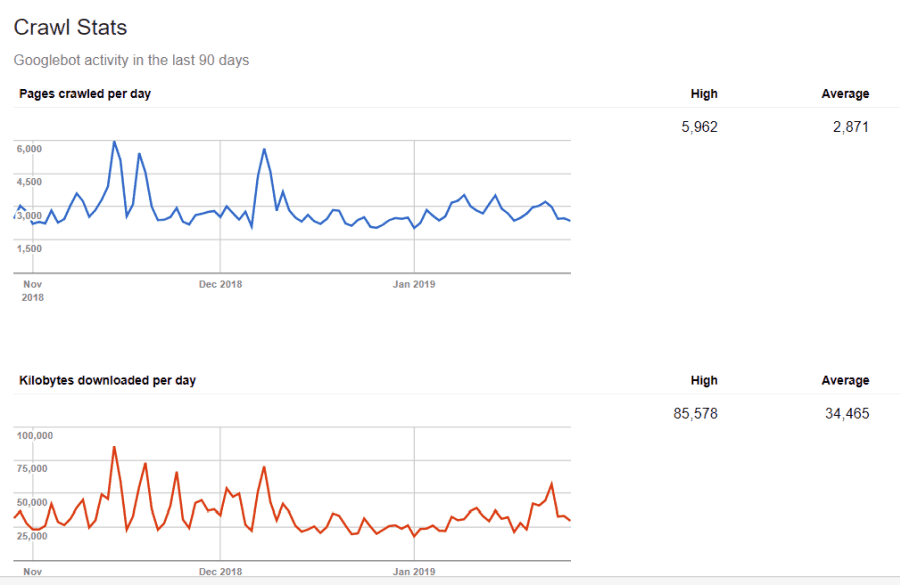
كما ترى ، يحافظ الزاحف على نشاطه على موقعك ثابتًا جدًا كل يوم. لا يزحف إلى جميع المواقع ، ولكن فقط المواقع التي يعتبرها الأكثر أهمية.
لماذا تترك الأمر لـ Googlebot لتحديد ما هو مهم على موقعك ، بينما يمكنك استخدام ملف robots.txt لإخباره ما هي أهم الصفحات؟ سيمنع هذا Googlebot من إضاعة الوقت في الصفحات منخفضة القيمة على موقعك.
تتيح لك أدوات مشرفي المواقع من Google أيضًا التحقق مما إذا كان Googlebot يقرأ ملف robots.txt بشكل جيد وما إذا كانت هناك أية أخطاء.
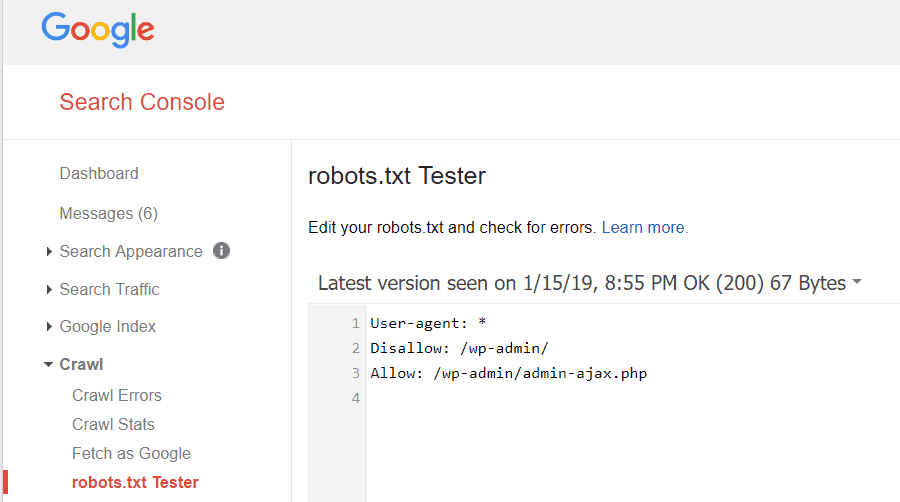
يساعدك هذا على التحقق من تنظيم ملف robots.txt بشكل صحيح.
ما الصفحات التي يجب عدم السماح بها من Googlebot؟ من الجيد أن يمنع موقعك تحسين محركات البحث الفئات التالية من الصفحات.
أكبر خطأ يرتكبه مالكو مواقع الويب الجدد هو عدم النظر أبدًا إلى ملف robots.txt الخاص بهم. قد يكون أسوأ موقف هو أن ملف robots.txt يحظر فعليًا الزحف إلى موقعك أو مناطق من موقعك على الإطلاق.
تأكد من مراجعة ملف robots.txt الخاص بك والتأكد من أنه محسن. بهذه الطريقة ، فإن Google ومحركات البحث المهمة الأخرى "ترى" جميع الأشياء الرائعة التي تقدمها للعالم من خلال موقع الويب الخاص بك.

